
A fundamental requirement to perform text mining is to get your text in a tidy format and perform word frequency analysis. Text is often in an unstructured format so performing even the most basic analysis requires some re-structuring. Thus, this first text mining tutorial covers the basics of text tidying and basic word frequency analysis.
This tutorial serves as an introduction to basic text mining. First, I provide the data and packages required to replicate the analysis in this tutorial and then I walk through the basic operations to tidy unstructured text and perform word frequency analysis.
This tutorial leverages the data provided in the harrypotter package. I constructed this package to supply the first seven novels in the Harry Potter series to illustrate text mining and analysis capabilities. You can load the harrypotter package with the following:
if (packageVersion("devtools") < 1.6) {
install.packages("devtools")
}
devtools::install_github("bradleyboehmke/harrypotter")
library(tidyverse) # data manipulation & plotting
library(stringr) # text cleaning and regular expressions
library(tidytext) # provides additional text mining functions
library(harrypotter) # provides the first seven novels of the Harry Potter series
The seven novels we are working with, and are provided by the harrypotter package, include:
philosophers_stone: Harry Potter and the Philosophers Stone (1997)chamber_of_secrets: Harry Potter and the Chamber of Secrets (1998)prisoner_of_azkaban: Harry Potter and the Prisoner of Azkaban (1999)goblet_of_fire: Harry Potter and the Goblet of Fire (2000)order_of_the_phoenix: Harry Potter and the Order of the Phoenix (2003)half_blood_prince: Harry Potter and the Half-Blood Prince (2005)deathly_hallows: Harry Potter and the Deathly Hallows (2007)Each text is in a character vector with each element representing a single chapter. For instance, the following illustrates the raw text of the first two chapters of the philosophers_stone:
philosophers_stone[1:2]
## [1] "THE BOY WHO LIVED Mr. and Mrs. Dursley, of number four, Privet Drive, were proud to say that they were perfectly normal, thank
## you very much. They were the last people you'd expect to be involved in anything strange or mysterious, because they just didn't hold
## with such nonsense. Mr. Dursley was the director of a firm called Grunnings, which made drills. He was a big, beefy man with hardly
## any neck, although he did have a very large mustache. Mrs. Dursley was thin and blonde and had nearly twice the usual amount of neck,
## which came in very useful as she spent so much of her time craning over garden fences, spying on the neighbors. The Dursleys had a
## small son called Dudley and in their opinion there was no finer boy anywhere. The Dursleys had everything they wanted, but they also
## had a secret, and their greatest fear was that somebody would discover it. They didn't think they could bear it if anyone found out
## about the Potters. Mrs. Potter was Mrs. Dursley's sister, but they hadn'... <truncated>
## [2] "THE VANISHING GLASS Nearly ten years had passed since the Dursleys had woken up to find their nephew on the front step, but
## Privet Drive had hardly changed at all. The sun rose on the same tidy front gardens and lit up the brass number four on the Dursleys'
## front door; it crept into their living room, which was almost exactly the same as it had been on the night when Mr. Dursley had seen
## that fateful news report about the owls. Only the photographs on the mantelpiece really showed how much time had passed. Ten years ago,
## there had been lots of pictures of what looked like a large pink beach ball wearing different-colored bonnets -- but Dudley Dursley was
## no longer a baby, and now the photographs showed a large blond boy riding his first bicycle, on a carousel at the fair, playing a
## computer game with his father, being hugged and kissed by his mother. The room held no sign at all that another boy lived in the house,
## too. Yet Harry Potter was still there, asleep at the moment, but no... <truncated>
Although we can do some simple regex analysis on this character vector, to properly analyze this text we want to turn it into a data frame or tibble. To do this on the philosophers_stone novel we could perform the following:
text_tb <- tibble(chapter = seq_along(philosophers_stone),
text = philosophers_stone)
text_tb
## # A tibble: 17 × 2
## chapter
## <int>
## 1 1
## 2 2
## 3 3
## 4 4
## 5 5
## 6 6
## 7 7
## 8 8
## 9 9
## 10 10
## 11 11
## 12 12
## 13 13
## 14 14
## 15 15
## 16 16
## 17 17
## # ... with 1 more variables: text <chr>
This creates a 2-column tibble. The second column contains the full text for each chapter; however, this isn’t very conducive to future analyses. We can unnest these texts:
text_tb %>%
unnest_tokens(word, text)
## # A tibble: 77,875 × 2
## chapter word
## <int> <chr>
## 1 1 the
## 2 1 boy
## 3 1 who
## 4 1 lived
## 5 1 mr
## 6 1 and
## 7 1 mrs
## 8 1 dursley
## 9 1 of
## 10 1 number
## # ... with 77,865 more rows
Now we’ve split up the entire philosophers_stone text into a tibble that provides each word in each chapter. Its important to note that the unnest_token function does the following:
to_lower = FALSE argument to turn this off)This now lets us do some simple analysis on the philosophers_stone text; however, what if we want to analyze text across all seven novels? To do this we can perform the same steps by looping through each novel and then combining them.
titles <- c("Philosopher's Stone", "Chamber of Secrets", "Prisoner of Azkaban",
"Goblet of Fire", "Order of the Phoenix", "Half-Blood Prince",
"Deathly Hallows")
books <- list(philosophers_stone, chamber_of_secrets, prisoner_of_azkaban,
goblet_of_fire, order_of_the_phoenix, half_blood_prince,
deathly_hallows)
series <- tibble()
for(i in seq_along(titles)) {
clean <- tibble(chapter = seq_along(books[[i]]),
text = books[[i]]) %>%
unnest_tokens(word, text) %>%
mutate(book = titles[i]) %>%
select(book, everything())
series <- rbind(series, clean)
}
# set factor to keep books in order of publication
series$book <- factor(series$book, levels = rev(titles))
series
## # A tibble: 1,089,386 × 3
## book chapter word
## * <fctr> <int> <chr>
## 1 Philosopher's Stone 1 the
## 2 Philosopher's Stone 1 boy
## 3 Philosopher's Stone 1 who
## 4 Philosopher's Stone 1 lived
## 5 Philosopher's Stone 1 mr
## 6 Philosopher's Stone 1 and
## 7 Philosopher's Stone 1 mrs
## 8 Philosopher's Stone 1 dursley
## 9 Philosopher's Stone 1 of
## 10 Philosopher's Stone 1 number
## # ... with 1,089,376 more rows
We now have a tidy tibble with every individual word by chapter by book. We can now proceed to perform some simple word frequency analyses.
The simplest word frequency analysis is assessing the most common words in text. We can use count to assess the most common words across all the text in the Harry Potter series.
series %>%
count(word, sort = TRUE)
## # A tibble: 24,475 × 2
## word n
## <chr> <int>
## 1 the 51593
## 2 and 27430
## 3 to 26985
## 4 of 21802
## 5 a 20966
## 6 he 20322
## 7 harry 16557
## 8 was 15631
## 9 said 14398
## 10 his 14264
## # ... with 24,465 more rows
One thing you will notice is that a lot of the most common words are not very informative (i.e. the, and, to, of, a, he, …). These are considered stop words. Most of the time we want our text mining to identify words that provide context (i.e. harry, dumbledore, granger, afraid, etc.). Thus, we can remove the stop words from our tibble with anti_join and the built-in stop_words data set provided by tidytext. Now we start to see characters and other nouns, verbs, and adjectives that we would expect to be common in this series.
series %>%
anti_join(stop_words) %>%
count(word, sort = TRUE)
## # A tibble: 23,795 × 2
## word n
## <chr> <int>
## 1 harry 16557
## 2 ron 5750
## 3 hermione 4912
## 4 dumbledore 2873
## 5 looked 2344
## 6 professor 2006
## 7 hagrid 1732
## 8 time 1713
## 9 wand 1639
## 10 eyes 1604
## # ... with 23,785 more rows
We can perform this same assessment but grouped by book or even each chapter within each book.
# top 10 most common words in each book
series %>%
anti_join(stop_words) %>%
group_by(book) %>%
count(word, sort = TRUE) %>%
top_n(10)
## Source: local data frame [70 x 3]
## Groups: book [7]
##
## book word n
## <fctr> <chr> <int>
## 1 Order of the Phoenix harry 3730
## 2 Goblet of Fire harry 2936
## 3 Deathly Hallows harry 2770
## 4 Half-Blood Prince harry 2581
## 5 Prisoner of Azkaban harry 1824
## 6 Chamber of Secrets harry 1503
## 7 Order of the Phoenix hermione 1220
## 8 Philosopher's Stone harry 1213
## 9 Order of the Phoenix ron 1189
## 10 Deathly Hallows hermione 1077
## # ... with 60 more rows
We can visualize this with
# top 10 most common words in each book
series %>%
anti_join(stop_words) %>%
group_by(book) %>%
count(word, sort = TRUE) %>%
top_n(10) %>%
ungroup() %>%
mutate(book = factor(book, levels = titles),
text_order = nrow(.):1) %>%
ggplot(aes(reorder(word, text_order), n, fill = book)) +
geom_bar(stat = "identity") +
facet_wrap(~ book, scales = "free_y") +
labs(x = "NULL", y = "Frequency") +
coord_flip() +
theme(legend.position="none")
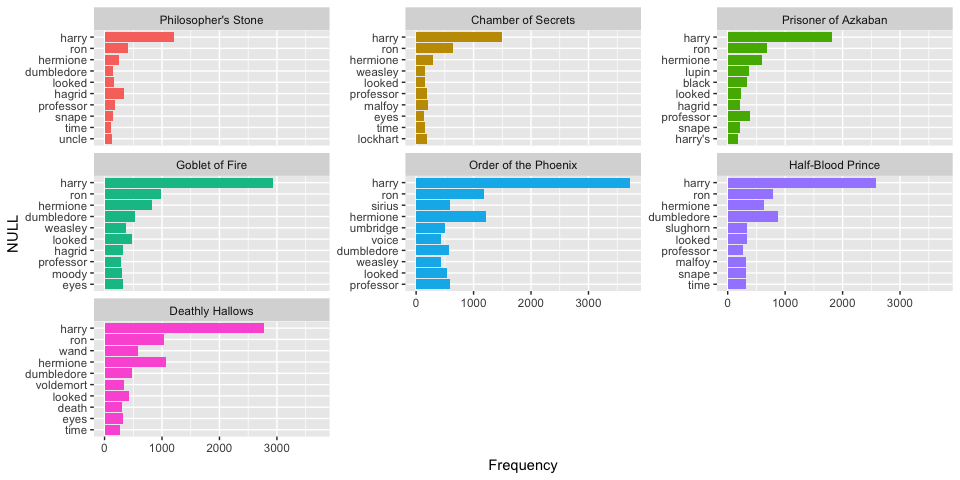
Now, let’s calculate the frequency for each word across the entire Harry Potter series versus within each book. This will allow us to compare strong deviations of word frequency within each book as compared to across the entire series.
# calculate percent of word use across all novels
potter_pct <- series %>%
anti_join(stop_words) %>%
count(word) %>%
transmute(word, all_words = n / sum(n))
# calculate percent of word use within each novel
frequency <- series %>%
anti_join(stop_words) %>%
count(book, word) %>%
mutate(book_words = n / sum(n)) %>%
left_join(potter_pct) %>%
arrange(desc(book_words)) %>%
ungroup()
frequency
## # A tibble: 63,651 × 5
## book word n book_words all_words
## <fctr> <chr> <int> <dbl> <dbl>
## 1 Chamber of Secrets harry 1503 0.04470420 0.04044824
## 2 Prisoner of Azkaban harry 1824 0.04428474 0.04044824
## 3 Philosopher's Stone harry 1213 0.04243484 0.04044824
## 4 Half-Blood Prince harry 2581 0.04090462 0.04044824
## 5 Goblet of Fire harry 2936 0.04040571 0.04044824
## 6 Order of the Phoenix harry 3730 0.03854222 0.04044824
## 7 Deathly Hallows harry 2770 0.03773533 0.04044824
## 8 Chamber of Secrets ron 650 0.01933315 0.01404707
## 9 Prisoner of Azkaban ron 690 0.01675245 0.01404707
## 10 Deathly Hallows hermione 1077 0.01467183 0.01199986
## # ... with 63,641 more rows
We can visualize this
ggplot(frequency, aes(x = book_words, y = all_words, color = abs(all_words - book_words))) +
geom_abline(color = "gray40", lty = 2) +
geom_jitter(alpha = 0.1, size = 2.5, width = 0.3, height = 0.3) +
geom_text(aes(label = word), check_overlap = TRUE, vjust = 1.5) +
scale_x_log10(labels = scales::percent_format()) +
scale_y_log10(labels = scales::percent_format()) +
scale_color_gradient(limits = c(0, 0.001), low = "darkslategray4", high = "gray75") +
facet_wrap(~ book, ncol = 2) +
theme(legend.position="none") +
labs(y = "Harry Potter Series", x = NULL)
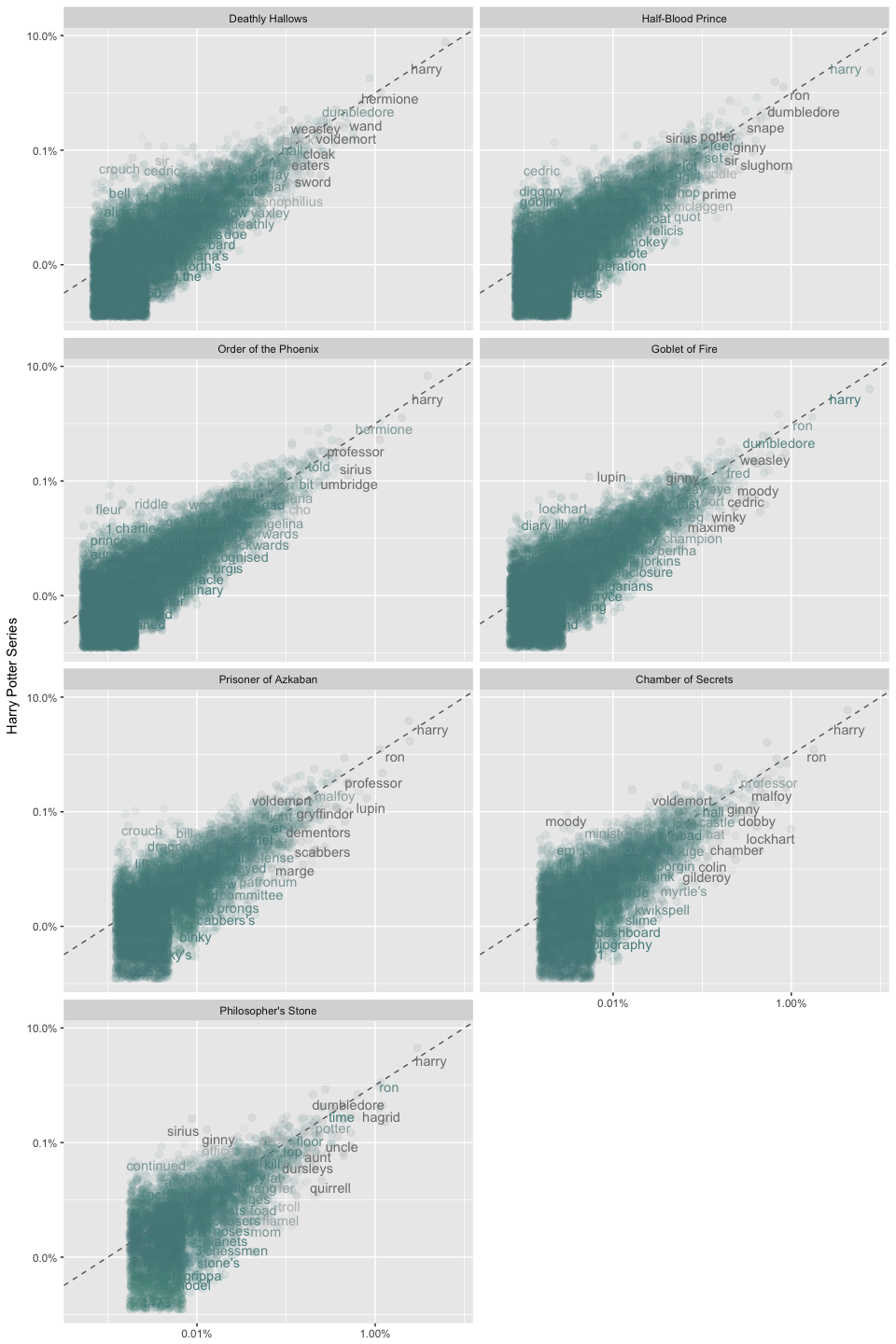
Words that are close to the line in these plots have similar frequencies across all the novels. For example, words such as “harry”, “ron”, “dumbledore” are fairly common and used with similar frequencies across most of the books. Words that are far from the line are words that are found more in one set of texts than another. Furthermore, words standing out above the line are common across the series but not within that book; whereas words below the line are common in that particular book but not across the series. For example, “cedric” stands out above the line in the Half-Blood Prince. This means that “cedric” is fairly common across the entire Harry Potter series but is not used as much in Half-Blood Prince. In contrast, a word below the line such as “quirrell” in the Philosopher’s Stone suggests this word is common in this novel but far less common across the series.
Let’s quantify how similar and different these sets of word frequencies are using a correlation test. How correlated are the word frequencies between the entire series and each book?
frequency %>%
group_by(book) %>%
summarize(correlation = cor(book_words, all_words),
p_value = cor.test(book_words, all_words)$p.value)
## # A tibble: 7 × 3
## book correlation p_value
## <fctr> <dbl> <dbl>
## 1 Deathly Hallows 0.9703948 0
## 2 Half-Blood Prince 0.9703266 0
## 3 Order of the Phoenix 0.9844414 0
## 4 Goblet of Fire 0.9793959 0
## 5 Prisoner of Azkaban 0.9641515 0
## 6 Chamber of Secrets 0.9656789 0
## 7 Philosopher's Stone 0.9551352 0
The high correlations, which are all statistically significant (p-values < 0.0001), suggests that the relationship between the word frequencies is highly similar across the entire Harry Potter series.
chamber_of_secrets book so that your text data are organized by chapter and unnested by word. See how your output changes by unnesting by bi-grams and tri-grams.chamber_of_secrets book by identifying:
philosophers_stone and chamber_of_secrets (at the book level, not chapter level). Can you figure out how to compare how similar (or different) the word frequencies are in these two books?